一、爬取数据
话不多说了,直接上代码( copy即可用 )
import requests
import pandas as pd
class SpiderRumor(object):
def __init__(self):
self.url = "https://vp.fact.qq.com/loadmore"
self.header = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1",
}
def spider_run(self):
df_all = list()
for url in [self.url % i for i in range(30)]:
data_list = requests.get(url, headers=self.header).json()["content"]
temp_data = [[df["title"], df["date"], df["result"], df["explain"], df["tag"]] for df in data_list]
df_all.extend(temp_data)
print(temp_data[0])
pd.DataFrame(df_all, columns=["title", "date", "result", "explain", "tag"]).to_csv("冠状病毒谣言数据.csv", encoding="utf_8_sig")
if __name__ == '__main__':
spider = SpiderRumor()
spider.spider_run()
爬虫过程

二、数据分析
数据展示

每日谣言数量

由图可得:1月24日和1月25日是谣言的高峰期,让我们来看看这两天的数据:

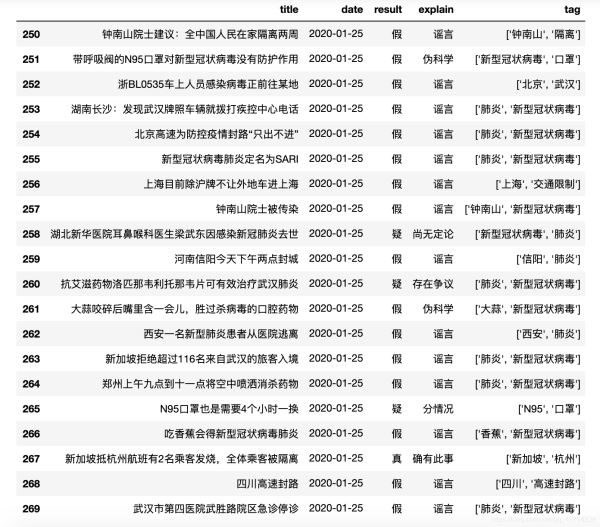
由上图得知 一月二十四号和二十号传播的 29 条谣言中 96.55% 都是假的
谣言是否属实占比

从1月18日到今日截止2月14日共发现了300条谣言,右上图可得:76.33% 都是假的,只要 7.00% 是属实的,其中 14.33% 的谣言属于 伪科学 而且 还有 8.00% 属于尚无定论凭空捏造出的,需要多注意"text-align: center">
下面介绍 matplotlib 绘制饼图的代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("/冠状病毒谣言数据.csv"")
labels = data["explain"].value_counts().index.tolist()
sizes = data["explain"].value_counts().values.tolist()
colors = ['lightgreen', 'gold', 'lightskyblue', 'lightcoral']
plt.figure(figsize=(15,8))
plt.pie(sizes, labels=labels,
colors=colors, autopct='%1.1f%%', shadow=True, startangle=50) # shadow=True 表示阴影
plt.axis('equal') # 使图居中
plt.show()
绘制谣言关键字分布图(观察 tag 这个字段)

由于 tag 这个字段内容是列表,我们取出来后是列表嵌套列表:[[a, b], [b, c], [c, d]] 我们要使用一行列表生成式快速的将所以的关键字取出来 [j for i in a for j in i]
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("/冠状病毒谣言数据.csv"")
df = pd.Series([j for i in [eval(i) for i in data["tag"].tolist()] for j in i]).value_counts()[:20]
X = df.index.tolist()
y = df.values.tolist()
plt.figure(figsize=(15, 8)) # 设置画布
plt.bar(X, y, color="orange")
plt.tight_layout()
# plt.grid(axis="y")
plt.grid(ls='-.')
plt.show()
总结
以上所述是小编给大家介绍的Python爬取新型冠状病毒“谣言”新闻进行数据分析,希望对大家有所帮助!
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件!
如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
暂无“Python爬取新型冠状病毒“谣言”新闻进行数据分析”评论...
一口气升级7个大模型SaaS应用,百度智能云:突出一个“开箱即用” - 2026/6/30
这一波大模型产业落地浪潮里,不少企业其实处在 “干瞪眼“的状态。
一种情况是,很多大模型产品看得见却摸不着,在台上一个个遥遥领先——今天Sora技精四座,明天英伟达的机器人又赢得满堂彩,可是到了台下一问:啥时候能用上啊?答曰:遥遥无期。
另一种情况是,企业想用上大模型,却又难免瞻前顾后——既要考虑场景融合,又得兼顾安全性,还要考虑打通现有系统,再加上各种部署成本和繁琐的采购流程……最后只能拂袖:罢了,再等等吧。
这一波大模型产业落地浪潮里,不少企业其实处在 “干瞪眼“的状态。
一种情况是,很多大模型产品看得见却摸不着,在台上一个个遥遥领先——今天Sora技精四座,明天英伟达的机器人又赢得满堂彩,可是到了台下一问:啥时候能用上啊?答曰:遥遥无期。
另一种情况是,企业想用上大模型,却又难免瞻前顾后——既要考虑场景融合,又得兼顾安全性,还要考虑打通现有系统,再加上各种部署成本和繁琐的采购流程……最后只能拂袖:罢了,再等等吧。
稳了!魔兽国服回归的3条重磅消息!官宣时间再确认!
昨天有一位朋友在大神群里分享,自己亚服账号被封号之后居然弹出了国服的封号信息对话框。
这里面让他访问的是一个国服的战网网址,com.cn和后面的zh都非常明白地表明这就是国服战网。
而他在复制这个网址并且进行登录之后,确实是网易的网址,也就是我们熟悉的停服之后国服发布的暴雪游戏产品运营到期开放退款的说明。这是一件比较奇怪的事情,因为以前都没有出现这样的情况,现在突然提示跳转到国服战网的网址,是不是说明了简体中文客户端已经开始进行更新了呢?
更新动态
2026年06月30日
2026年06月30日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]