[md]# gb688预览-浏览器保存pdf下载的方法思路
前言(说点废话,与题目无关,算有感而发吧)
- 吾爱论坛自我感觉是我心中真正的技术论坛,自己是做web前端,喜欢web领域的逆向,奈何自己水平太低,只能打工维持生活,自己连基本混淆和复杂的解密都搞不定,每当自己对技术懈怠时, 就会去论坛看最新技术文章 ,尤其是自己每次阅读到优秀的技术文章时,都感觉自愧不如自己只掌握了前端的皮毛,当然也使自己受益良多提高了自己的逆向兴趣和技术的热爱.自己也白嫖了论坛好多软件,学习视频和资料.
- 当然良好发展离不开论坛优秀的管理员和管理制度,吾爱一直坚持原创,产生了很多优秀的文章.论坛文章的排版格式阅读体验也非常好我阅读越来很轻松.
- 最后,祝吾爱不忘初心,在未来的技术道路上越来越好(我在干什么,开局送祝福?).
言归正传
故事要从一次聊天说起,群里一个人(刚子)发了一个链接问有人能下载这个pdf吗,当时我看到是一个链接,由于在公司无法用公司电脑查看链接,就说了能帮你他下载,但需要等下班用自己电脑帮他下载.
我当时给他说,不是要pdf吗,直接ctrl+p保存为pdf就行了,他说不行,保存时是空白页面,我当时以为浏览器不支持保存pdf就没多想.
于是下班回去用自己的电脑chrome浏览器打开老哥的链接(下面附链接),打开要输入验证码后页面显示出来.
- 链接-浏览器btoa生成的(aHR0cDovL2MuZ2I2ODguY24vYnpnay9nYi9zaG93R2I/dHlwZT1vbmxpbmUmaGNubz0zNDBCQ0UzMzYzNkU0MjY3MEY5RjU5NUM5NURCODkwQQ==)
- 思路一
- 自己首先是要打开浏览器开发者工具来debug, f12居然没反应,右键也没反应,最后ctrl+shift+i才把devtool显示出来.
- 页面看起来是图片,就想着这些图片是怎么来的,于是重新请求进行抓包,当自己抓到图片的包,看起来和页面大差不差时,自己内心是愉悦的,想着把这些图片下载起来就行了,当自己下载下来图片点开看时,发现都是图片显示残缺的一部分,心里默默念了mmp
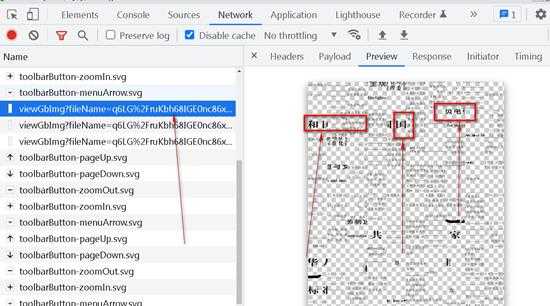
- 但转念一想,不对啊,这种残缺图片,它的页面怎么就能正常展示呢,于是自己进入审查元素查看DOM结构,发现,它都是通过span元素的背景图片显示的,把多张背景通过算法计算位置叠加到一起,显示出完整页面(这个展示思路有点厉害)
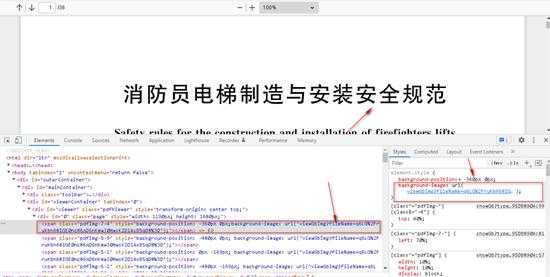

- 于是产生了一种思路,就是自己拿到多张图片,根据算法叠加到一块,就能把页面展示出来,由于不知道什么算法,自己也不会叠加,于是这种思路卒.
- 思路二
- 那就使用chrome浏览器自带打印功能保存为pdf,右键点击打印发现右键没反应,原来把右键菜单屏蔽了,那就ctrl+p出来弹窗,选择保存pdf,但预览显示空白,自己还以为是浏览器预览的问题,直接保存,找到保存文件一看0kb,打开是空白,自己也没多想,就以为浏览器不支持打印,于是这种思路又卒.
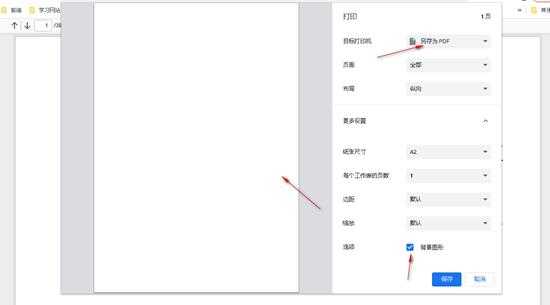
- 那就使用chrome浏览器自带打印功能保存为pdf,右键点击打印发现右键没反应,原来把右键菜单屏蔽了,那就ctrl+p出来弹窗,选择保存pdf,但预览显示空白,自己还以为是浏览器预览的问题,直接保存,找到保存文件一看0kb,打开是空白,自己也没多想,就以为浏览器不支持打印,于是这种思路又卒.
- 思路三
- 碰到难题,就打开论坛找老哥解决,于是论坛搜索gb6**,看到了一些相关的帖子,说的网站升级了,之前一句js代码就能下载,再到后来手机版接口能下载pdf版本,但现在升级了,都不能下载了,还找到了一些关于讨论下载技术的帖子,当然肯定有大佬能下载,只是没公开出来或者我没找到.自己一看都升级了连大佬也没办法,于是这种思路也卒
相关帖子链接
- 碰到难题,就打开论坛找老哥解决,于是论坛搜索gb6**,看到了一些相关的帖子,说的网站升级了,之前一句js代码就能下载,再到后来手机版接口能下载pdf版本,但现在升级了,都不能下载了,还找到了一些关于讨论下载技术的帖子,当然肯定有大佬能下载,只是没公开出来或者我没找到.自己一看都升级了连大佬也没办法,于是这种思路也卒
自己当时是搞不定了,于是当天晚上回群友消息,网站太牛逼自己搞不定
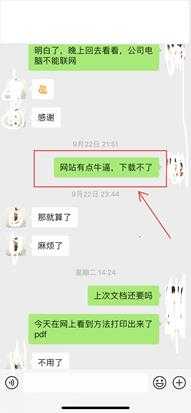
正片开始
链接(aHR0cDovL2MuZ2I2ODguY24vYnpnay9nYi9zaG93R2I/dHlwZT1vbmxpbmUmaGNubz0zNDBCQ0UzMzYzNkU0MjY3MEY5RjU5NUM5NURCODkwQQ==)
上图也可以看出,时隔多日搞出来了下载,但群友最后已经不需要了,于是自己分享出来
过程是自己在看论坛精华技术文章时,感叹大佬文章写的真好同时,想到之前链接为什么浏览器打印保存pdf是空白,于是自己随便找了几个网站,保存pdf,发现预览都是有内容的,而且保存后打开是正常的pdf格式,于是想到是不是网站对保存pdf作了手脚,于是自己马上兴趣来了,去谷歌输入: 浏览器如何禁用保存pdf功能.于是找到一条有用线索:
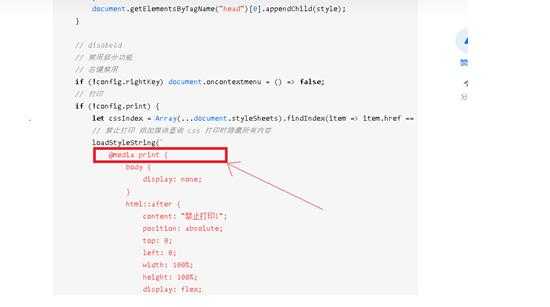
于是自己赶紧在网站下全局搜索这个 home.php?mod=space&uid=945662 print,果然搜索出了好多信息
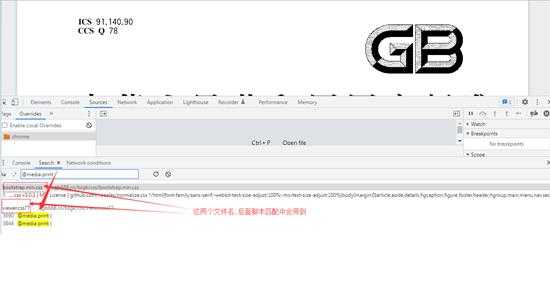
自己心想自己把 @media print 删除掉会不会就能打印了,于是自己删除掉一个调出保存pdf预览功能,果然空白的页面显示出来一些边框,自己内心狂喜,把这些 @media print 都删除掉不就是能保存pdf了.
那么自己怎么把资源文件 @media print 全部删除?
- 自己手动删除,通过浏览器的overrides功能覆盖掉,自己debug时采用的这种
- 先通过浏览器找到哪些文件含有 @media print 通过fildder拦截响应,再利用正则把 @media print 替换掉,文章中采用这种
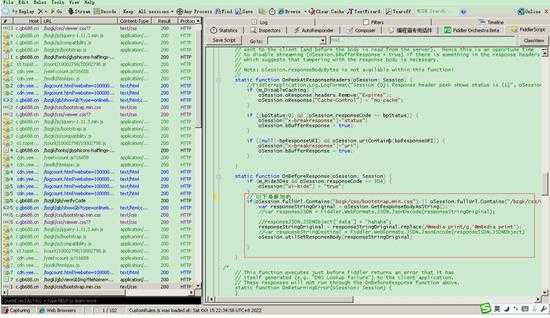
// 以下是新加的 if(oSession.fullUrl.Contains("/bzgk/css/bootstrap.min.css") || oSession.fullUrl.Contains("/bzgk/css/viewer.css")){ var responseStringOriginal = oSession.GetResponseBodyAsString(); responseStringOriginal = responseStringOriginal.replace(/@media print/g,'@m8edia print'); oSession.utilSetResponseBody(responseStringOriginal) }
- 于是自己保存为pdf时,内容就显示出来了(要勾选背景图形)
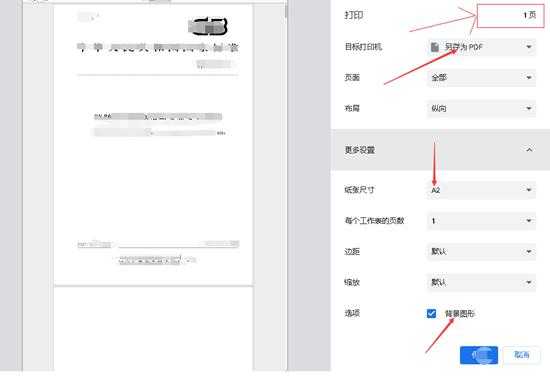
- 但是却只能打印一页,自己去查看DOM结构,发现有个元素overflow:auto于是就把这个去掉
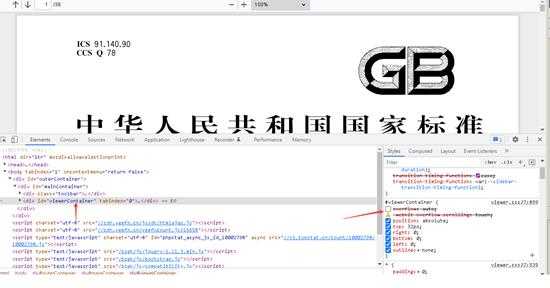
- 上面再保存时,就显示了29页,自己保存下来,发现文件大小只有1M,不对啊,上次调试保存下来,文件有8M大小,于是找原因发现页面采用了懒加载,只有把网页页面拖动到最后,dom才会把所有的图片加载出来,保存pdf时后面的页面才会显示出来
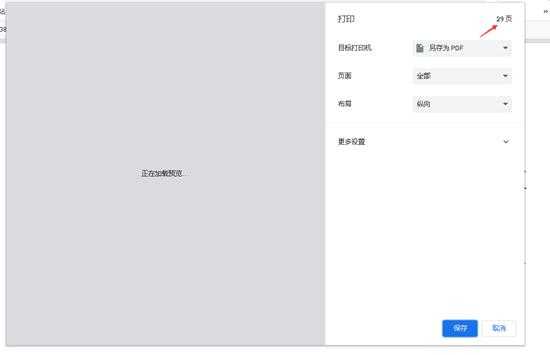
- 自己保存下来,文件有8M多,自己通过pdf也能正常打开,上面还是有水印的
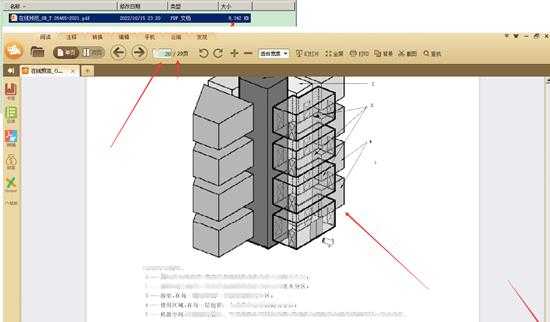
至此全文结束,感谢你的阅读(可以利用此思路来保存你想要保存任何预览是空白的网页).